

Рассмотрим детали работы парсера фото или картинок с сайта. Фото будут скачиваться и сохраняться на ваш компьютер или сервер, на котором запускается PHP скрипт парсера. Скачивать будем картинки из карточки товара интернет-магазина gearbest.com.
Для начала нужно собрать URL фото товаров из HTML кода карточки товара.
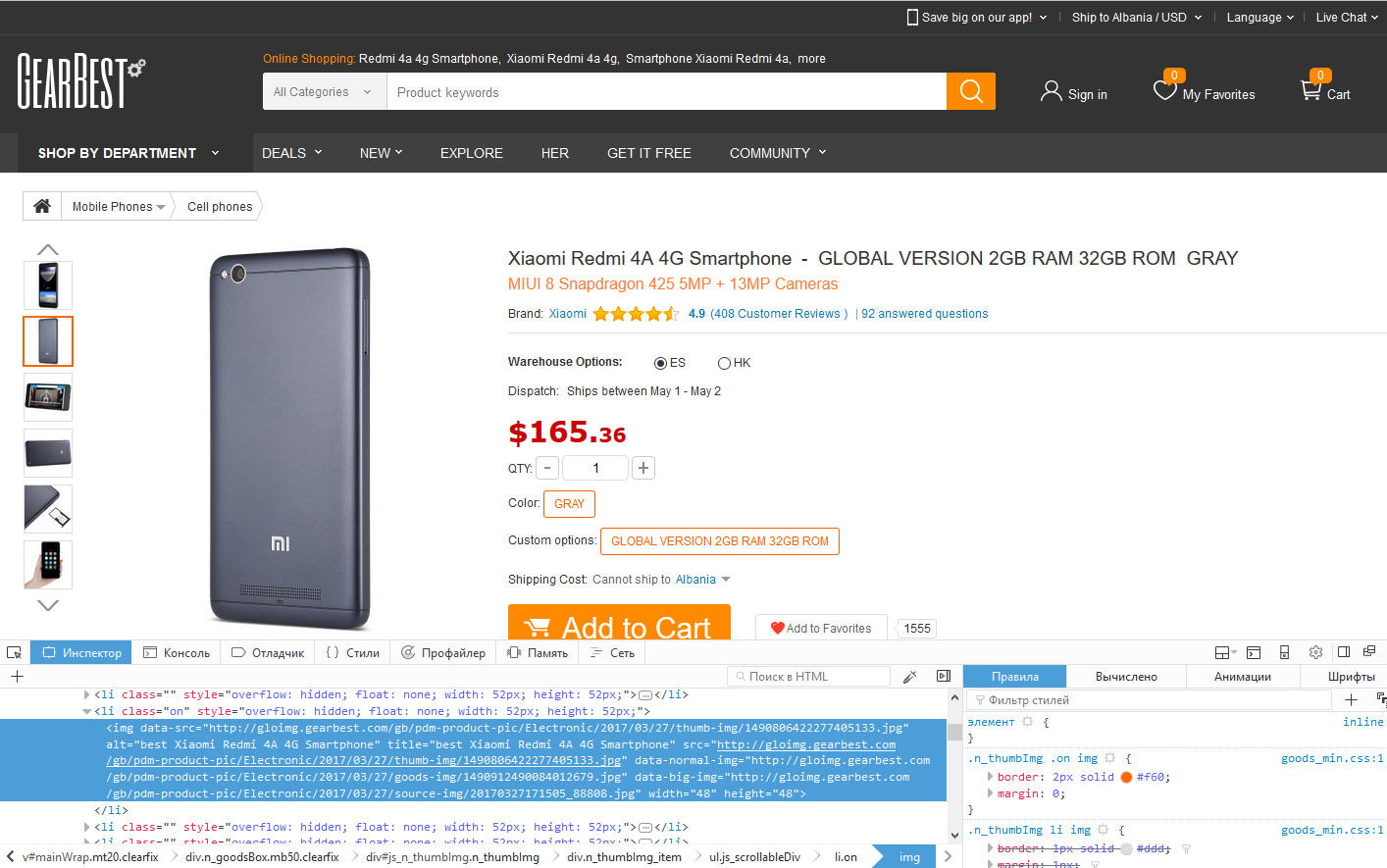
Для этого можно применить простой парсер HTML, который рассматривался в первой статье цикла.
После получения списка ссылок на фото товара мы скачиваем сами картинки с помощью той же функции получения данных от сервера на основе cURL. Можно было бы даже воспользоваться стандартной функцией PHP file_get_contents(). Но в нашей функции curl_get_contents() реализована возможность повторной попытки скачать файл и пауза между запросами к серверу. Это бывает полезно, когда попадаются сайты с защитой от множественных загрузок или просто слабые сервера, которые не выдерживают повышенные нагрузки.

Парсер фото товара с сайта
В результате получаем простой парсер фото товаров с сайта на примере gearbest.com. Код парсера размещён в одном файле, часть возможных ошибок не обрабатывается для краткости кода.
Исходный код index.php:
<?php
Error_Reporting(E_ALL & ~E_NOTICE);
mb_internal_encoding("UTF-8");
set_time_limit(0); // Попытка установить своё время выполнения скрипта
/* --- 1 --- Инициализируем переменные для запроса */
$time_start = time();
$error = array();
$error_page = array();
$action = 0;
$gearbest_url = "";
$charset = "UTF-8"; // Исходная кодировка страницы
$uni_name = date("d-m-Y-H-i-s", time());
/* --- 1.1 --- Переопределяем переменные на основе GET или POST параметров */
if(isset($_REQUEST['gearbest_url']))
$gearbest_url = trim($_REQUEST['gearbest_url']);
if(isset($_REQUEST['action']))
$action = $_REQUEST['action'];
/* --- 1.2 --- Запросы при помощи cURL */
/* --- 1.2.1 --- Загрузка страницы при помощи cURL */
function curl_get_contents($page_url, $base_url, $pause_time, $retry) {
/*
$page_url - адрес страницы-источника
$base_url - адрес страницы для поля REFERER
$pause_time - пауза между попытками парсинга
$retry - 0 - не повторять запрос, 1 - повторить запрос при неудаче
*/
$error_page = array();
$ch = curl_init();
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0");
curl_setopt($ch, CURLOPT_COOKIEJAR, str_replace("\\", "/", getcwd()).'/gearbest.txt');
curl_setopt($ch, CURLOPT_COOKIEFILE, str_replace("\\", "/", getcwd()).'/gearbest.txt');
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // Автоматом идём по редиректам
curl_setopt ($ch, CURLOPT_SSL_VERIFYPEER, 0); // Не проверять SSL сертификат
curl_setopt ($ch, CURLOPT_SSL_VERIFYHOST, 0); // Не проверять Host SSL сертификата
curl_setopt($ch, CURLOPT_URL, $page_url); // Куда отправляем
curl_setopt($ch, CURLOPT_REFERER, $base_url); // Откуда пришли
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Возвращаем, но не выводим на экран результат
$response['html'] = curl_exec($ch);
$info = curl_getinfo($ch);
if($info['http_code'] != 200 && $info['http_code'] != 404) {
$error_page[] = array(1, $page_url, $info['http_code']);
if($retry) {
sleep($pause_time);
$response['html'] = curl_exec($ch);
$info = curl_getinfo($ch);
if($info['http_code'] != 200 && $info['http_code'] != 404)
$error_page[] = array(2, $page_url, $info['http_code']);
}
}
$response['code'] = $info['http_code'];
$response['errors'] = $error_page;
curl_close($ch);
return $response;
}
/* --- 1.3 --- Функции для Gearbest.com */
/* --- 1.3.1 --- Парсинг URL фото */
function get_gearbest_foto_urls($gearbest_url) {
/*
$gearbest_url - адрес страницы товара на Gearbest
*/
$res_arr = array();
$res_arr['foto_urls'] = array();
$base_url = "https://www.gearbest.com";
// Получаем HTML код страницы карточки товара / опускаем проверку ошибок
$response_arr = curl_get_contents($gearbest_url, $base_url, 5, 1);
$gearbest_page = $response_arr['html'];
// Парсим URL адреса картинок
$regexp = "/data-big-img=\"(.+)\"/Us";
$buffer = array();
preg_match_all($regexp, $gearbest_page, $buffer);
$res_arr['foto_urls'] = $buffer[1];
$urls_arr = array();
$res_arr['errors'] = array();
return $res_arr;
}
/* --- 1.3.2 --- Скачиваем и сохраняем фото */
function get_gearbest_foto($foto_urls) {
/*
$foto_urls - массив URLs фото товара на Gearbest
*/
$res_arr = array();
$res_arr['errors'] = array();
$res_arr["foto_info"] = array();
$res_arr["count_all"] = $res_arr["count_ok"] = 0;
$base_url = "https://www.gearbest.com";
$catalog_out_path = "images";
if(!is_dir($catalog_out_path)) {
mkdir($catalog_out_path, 0777, true);
}
// Скачиваем фото и записываем их в каталог images / частично опускаем проверку ошибок
foreach($foto_urls as $key => $url) {
$foto_name = mb_substr($url, (mb_strpos($url, "source-img/") + 11));
$response_arr = curl_get_contents($url, $base_url, 5, 1);
$foto_content = $response_arr['html'];
if(file_put_contents($catalog_out_path . "/" . $foto_name, $foto_content)) {
$res_arr["count_ok"]++;
$res_arr["foto_info"][$key]["url"] = $url;
$res_arr["foto_info"][$key]["local_url"] = $catalog_out_path . "/" . $foto_name;
} else {
$res_arr["foto_info"][$key]["url"] = $url;
$res_arr["foto_info"][$key]["local_url"] = "no_url";
$res_arr['errors'] = "Ошибка записи фото: " . $url;
}
$res_arr["count_all"]++;
}
return $res_arr;
}
/* --- 1.4 --- Вывод данных в HTML */
/* --- 1.4.1 --- Вывод информации о спарсенных фото */
function foto_list_html($res_arr) {
echo "Удачно собрано " . $res_arr["count_ok"] . " из " . $res_arr["count_all"] . " фото.";
foreach($res_arr["foto_info"] as $key => $foto_info) {
echo "<p>" . $foto_info["url"] . " - " . $foto_info["local_url"] . "</p>";
}
}
/* --- 1.4.2 --- Вывод ошибок */
function error_list_html($errors) {
if (!empty($errors)) {
echo "<p>Во время сбора фото произошли следующие ошибки:</p>\n";
echo "<ul>\n";
foreach($errors as $error_row) {
echo "<li>" . $error_row . "</li>\n";
}
echo "</ul>\n";
echo "<p>Статус: <span class=\"red\">FAIL</span></p>\n";
} else {
echo "<p>Статус: <span class=\"green\">OK</span></p>\n";
}
}
/* --- 1.4.3 --- Вывод времени работы скрипта */
function run_time_html($time_start) {
if(!empty($time_start))
echo "<p>Время работы скрипта: " . (time() - $time_start) . "</p>\n";
}
/* --- 2 --- Получение контента с сайта Gearbest */
if($action) { // Спарсить условия доставки товара товара
if(!empty($gearbest_url)) {
$gearbest_url = trim($gearbest_url);
$din_url = $gearbest_url;
$res_arr = get_gearbest_foto_urls($din_url);
if(!empty($res_arr['foto_urls'])) {
$res_arr = get_gearbest_foto($res_arr['foto_urls']);
} else {
$res_arr['errors'][] = "Ошибка сбора адресов фото";
}
} else {
$res_arr['errors'][] = "Не задан адрес карточки товара";
}
}
/* --- 3 --- Вывод результатов работы парсера */
?>
<!doctype html>
<html>
<head>
<title>Парсер информации на Gearbest.com</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<!--meta name="robots" content="noindex,nofollow"-->
</head>
<body>
<style>
.wrapper {
max-width: 600px;
margin: 0 auto;
}
h1 {
text-align: center;
}
.action_form {
max-width: 560px;
margin: 0 auto;
}
.action_form input {
width: 100%;
}
input[type="text"] {
font-size: 1em;
min-height: 36px;
box-sizing: border-box;
}
input[type="submit"],
input[type="button"] {
padding: 8px 12px;
margin: 12px auto;
font-size: 1.2em;
font-weight: 400;
line-height: 1.2em;
text-decoration: none;
display: inline-block;
cursor: pointer;
border: 2px solid #007700;
border-radius: 2px;
background-color: transparent;
color: #007700;
}
input[type="submit"]:hover,
input[type="button"]:hover {
background-color: #009900;
color: #fff;
}
.result {
border: 1px dotted #000;
width: 100%;
height: auto;
overflow-y: auto;
margin: 0px auto;
padding: 10px;
}
.copyright {
text-align: center;
}
.copyright a {
color: #000;
}
.copyright a:hover {
text-decoration: none;
}
.red {
color: #770000;
}
.green {
color: #007700;
}
</style>
<div class="wrapper">
<h1>Парсер фото из карточки товара Gearbest.com</h1>
<form class="action_form" action="" method="post">
<input type="hidden" name="action" value="1" />
<input type="text" name="gearbest_url" value ="<?php if(!empty($gearbest_url)) echo $gearbest_url; ?>" placeholder="URL страницы товара" />
<input type="submit" name="submit" value="Собрать фото" />
</form>
<div class="result">
<?php
if($action && !empty($res_arr['foto_info'])) {
foto_list_html($res_arr);
}
?>
</div>
<div class="errors_block">
<?php
error_list_html($res_arr['errors']);
run_time_html($time_start);
?>
</div>
<div class="copyright">© Идея и реализация - <a href="https://seorubl.ru/" target="_blank" title="Записки Предприимчивого Человека" rel="generator">ПЧ</a> // 30.04.2017 г.</div>
</div>
</body>
</html>
Рассмотрим основные особенности. Парсер собирает фото с одной карточки товара. Но нам ничего не мешает при необходимости добавить ещё один цикл и спарсить картинки по списку страниц.
Обратите внимание на функцию preg_match_all(), она возвращает массив соответствий регулярному выражению. В этом её основное отличие от функции preg_match(), которая работает до первого совпадения.
С помощью встроенной в PHP функции file_put_contents() можно сохранить фото на свой сервер по нужному пути. Соответственно предварительно мы проверяем наличие нужного нам каталога и при его отсутствии создаём его.
Также при попытке достать из URL фото имя файла я показал пример работы с PHP функциями обработки строк mb_strpos() и mb_substr(). Ими полезно пользоваться в качестве альтернативы регулярным выражениям, работают быстрее. Префикс mb_ указывает на то, что данные функции корректно работают с многобайтными кодировками, в частности со строками на русском языке.
В результате работы парсера получаем список фото на своём жёстком диске в заданной папке и с заданными именами файлов.

Конечно, можно было бы организовать парсер по AJAX технологии, но у применённого подхода есть свои плюсы. Например, при большом количестве картинок и длительной работе парсера нам необязательно держать вкладку браузера открытой. PHP скрипт сможет долго работать на сервере и сохранять картинки в нужную директорию. При этом, правда, мы не увидим результаты выполнения скрипта. Но то же окончание работы парсера можно будет заметить по прекращению создания новых файлов с фото.
В следующих статьях из цикла про парсеры мы рассмотрим обработку CSV данных и парсинг с помощью специальных библиотек для работы с DOM данными в PHP на примере PHPquery. Оставайтесь на связи.
Довольно полезная статья, спасибо. С функцией preg_match_all(), возвращающей массив соответствий, не до конца понятно. Т.е. она по очереди проходит строки, находит первое совпадение с шаблоном, а потом ищет дальше, начиная с конца последнего найденного? Т.е. расширяет возможности preg_match()…
Да, именно так и работает функция. Ищет все вхождения один за другим. Надо только не забыть ограничить жадность операторов, а то могут получиться «неожиданные» результаты.